
Datenjournalismus: Methoden, Prozesse und Kompetenzen
Nahezu jede Branche und jedes Thema lässt sich mit Daten beschreiben. Das erfordert seitens der Bearbeiter – meist Redaktionen, aber auch freie Journalisten und Agenturen – Investitionen in Arbeitskraft und Infrastruktur. Die Vorteile, über das eigene Fach – gestützt auf Datenbanken – berichten zu können, sind mannigfaltig. Aber es gibt diverse Fallstricke – ein Überblick über Methoden, Prozesse und Kompetenzen.
Seit fünf Jahren ist die Rede von Datenjournalismus. Der Start des „Datablog“ auf der Website des britischen Guardian im Frühjahr 2009 ist dafür ein Anhaltspunkt. Ein Durchbruch für das Genre kam 2010 mit der ersten großen Enthüllung durch Wikileaks über die „Kriegstagebücher“ der US-Armee in Afghanistan: Durch interaktive Grafiken und Karten wurden die großen Mengen an Informationen digital anschaulich und zugänglich aufbereitet.
Die Methoden des Datenjournalismus bauen auf dem seit Jahrzehnten bekannten „Computer-assisted reporting“ (CAR) auf. Neu ist, dass die Datenbasis der Recherche gleichzeitig als Rohstoff für Visualisierungen – oft interaktiv und nicht-linear – im Netz genutzt wird. Mittlerweile hat sich der „data-driven-journalism“ im Digitalen etabliert; die Vielfalt des Genres lässt sich mittels Hashtag #ddj erspüren – darunter werden bei Twitter rege Praktiken ausgetauscht und neue Formate sowie Ansätze gezeigt; als Indikator, dass Datenjournalismus im Mainstream angekommen ist, mag auch der derzeit laufende erste internationale Onlinekurs (MOOC) des European Journalism Centre dienen: Er zählt circa 17.000 eingeschriebene Teilnehmer. Neben den Flaggschiffen des Genres, der New York Times und dem Guardian, setzen auch große Medien in Deutschland im Digitalen auf interaktive Anwendungen, wenn man so will „Datengeschichten“: Spiegel Online, Zeit Online und süddeutsche.de haben spezialisierte Teams aufgebaut.
Aber auch im Lokal- und im Fachjournalismus begegnen einem immer wieder datenjournalistische Werke. Während im Lokalen oft die alltäglichen Dinge im Vordergrund stehen – Bildung, Verkehr oder Kriminalität –, die gerne auf Karten visualisiert werden, lässt sich im Fachjournalismus die jeweilige Nische mittels Daten genauer beleuchten und beschreiben. Und welcher Fachjournalist hat nicht ständig mit Zahlen und Statistiken zu tun?
Meedia und andere Beispiele
Ein Beispiel: Die Branchenwebsite meedia.de hat unlängst einen Relaunch hingelegt und wenig später ein „Datencenter“ gestartet. Dieses bereitet die Einschaltquoten im Fernsehen und Auflagenzahlen von Periodika auf oder gibt die Klickzahlen für Onlinemedien wieder. Alles Daten, die Leuten vom Fach zwar bekannt und zugänglich sind. Aber Meedia bietet hier einen Mehrwert, hat ein „Analyzer Tool“ im Programm, das den Vergleich der Verkaufszahlen verschiedener Titel erlaubt. Zudem erspart es dem Besucher der Website die Mühe, sich die Daten auf teilweise umständliche Art erschließen zu müssen. Auf diese Weise dürfte sich Meedia auf Dauer als Anlaufstelle etablieren.
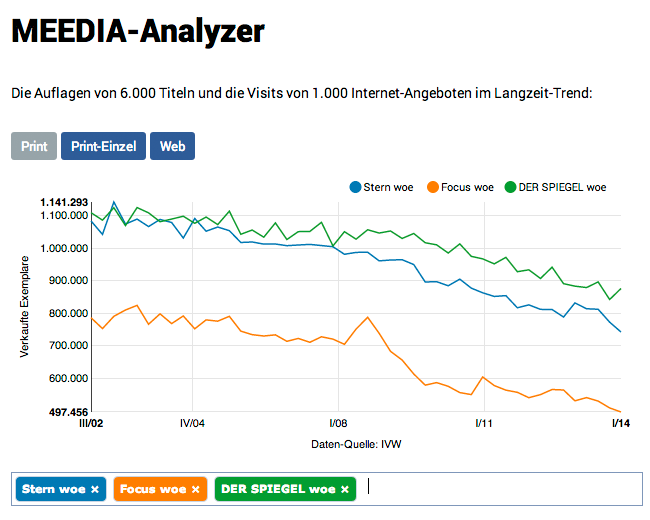
Die Auflagen der Wochenzeitschriften „Stern“, „Focus“ und „Der Spiegel“ im Zeitverlauf.
Quelle: http://meedia.de/datacenter/analyzer/meedia-data/print-00143,02952,00122/, aufgerufen am 11.06.2014
Solch ein Service kann allerdings nicht als Journalismus bezeichnet werden. Doch nutzt Meedia ihn offensichtlich selbst intern als Recherchewerkzeug, also für journalistische Zwecke: Im Rahmen seines „Datencenters“ werden zahlengespickte Berichte veröffentlicht. Gleichzeitig hat sich Meedia eine ausbaufähige Dateninfrastruktur geschaffen, die es erlaubt, in Zukunft weitere Dienste zu entwickeln; mit dem ständig wachsenden Datenbestand werden recht einfach Datenstücke möglich – etwa Hintergrundberichte über das vielzitierte „Zeitungssterben“, das anschaulich mit Fakten untermauert wird.
Seitens Meedia werden die regelmäßig veröffentlichten Daten, beispielsweise die der IVW (Informationsgemeinschaft zur Feststellung der Verbreitung von Werbeträgern), aus Tabellendateien eingelesen; damit wächst der Datensatz in der eigenen Datenbank stetig heran. Alles in allem dürfte es sich bei dem Vorhaben um eine überschaubare Investition gehandelt haben, denn die Visualisierung in Graphenform fußt auf gängigen Programmierbausteinen („Library“) und die Daten liegen bereits digital in strukturierter Form, als Excel-Tabellen, vor.
Ein Beispiel dafür, wie die Arbeit mit Daten monetisiert werden kann, zeigt die Lebensmittel Zeitung aus dem Deutschen Fachverlag: Hier dienen Daten als Anreiz, Abonnent zu werden. Denn die Redaktion trägt Kennzahlen und Rankings zusammen und bietet diese online hinter einem Login ihren Abonnenten zum Abruf an. Im Shop auf lebensmittelzeitung.de können zudem diverse datenlastige Reporte erworben werden.
Daten über Personen, Produkte und Institutionen fallen in jedem Sektor an. Für sein Fach die „Datenautorität“ zu werden, kann nur von Vorteil sein. So versuchen sich etwa freie Journalisten als Spezialisten für demografische Daten zu profilieren (demografie-blog.de); andere sind im Bereich Fußball unterwegs (fussballdoping.de, fussballverletzungen.wordpress.com).
Die Krux mit den Daten
Je nach Branche und Thema gibt es zwar viele Daten, aber oft werden die nicht als Datensätze zur Verfügung gestellt. Doch das muss das erste Ziel sein: Die Daten müssen sich weiter verarbeiten lassen, müssen in eine Datenbank überführt werden. Dabei kann es sich am Ende schlicht um eine Excel-Tabelle handeln oder eben ein komplexes Datenbanksystem. Erst dann können die Datensätze „befragt“ werden, lassen sie sich auswerten. Im Kern geht es darum, Erkenntnisse zu gewinnen. Etwa, indem nach nicht offensichtlichen Mustern oder Unregelmäßigkeiten geforscht wird.
Bei datenjournalistischen Vorhaben, so der Erfahrungswert des Autors, sind mindestens 50 Prozent der Arbeit damit verbunden, die Daten zu erheben und so aufzubereiten, dass sie sich überhaupt sinnvoll erschließen lassen. Es empfiehlt sich, von vornherein festzulegen, wie viel Arbeitszeit für ein Vorhaben in die Datenrecherche investiert werden soll. Und an welcher Stelle abgebrochen wird. Denn wenn zum Beispiel Daten aus verschiedenen Quellen zusammengeführt werden, kann sich bald zeigen, dass eine Vereinheitlichung nur mit einem nicht vertretbaren Aufwand möglich wird.
Leider ist es weiterhin üblich, etwa seitens Pressestellen, PDF-Dateien zu versenden. Ein Format, so heißt es in datenjournalistischen Kreisen, in dem Daten sterben. Aus ihnen die Informationen zu „befreien“, kann einiges an Arbeit bedeuten. Das kann vom simplen Export als Excel-Datei über manuelles Copy and Paste bis hin zur Schrifterkennung per OCR reichen. Manchmal hilft auch nichts anderes, als dass ein Programmierer einen „Scraper“ schreibt, einen Softwarecode, der die Daten ausliest. Das lohnt sich in der Regel nur ab vielen hundert Dateien oder wenn beispielsweise bekannt ist, dass monatlich ein Bericht in ein und derselben Form kommt.
Ideal wäre es, wenn etwa ein Branchenverband eine Schnittstelle (API – Application Programming Interface) zur Verfügung stellen würde und darüber Informationen schon als „Datenhappen“ anbietet. Das ist allerdings im Bereich der Öffentlichkeitsarbeit bislang nicht üblich. Eine Art Selbsthilfe stellt deswegen das „Scrapen“ dar; eine Methode, die einmalig oder in regelmäßigen Abständen bestimmte Informationen aus Websites ausliest und in einer Datenbank ablegt. Zwar gibt es dafür auch Lösungen für Nicht-Programmierer (z. B. kimonolabs.com), doch stößt man damit bald an Grenzen; der Einsatz eines Entwicklers wird unabdingbar. Dabei muss erwähnt werden: Schnell bewegt man sich dabei in einem rechtlichen Graubereich. Zwar fallen Datensammlungen in der Regel nicht unter das Urheberrecht, mangels Schöpfungshöhe. Doch gibt es ein „Datenbankschutzrecht“, das berücksichtigt werden muss.
Softwareentwicklung in der Redaktion
Durch Datenjournalismus halten Prozesse der Softwareentwicklung in Redaktionen Einzug. Denn nach der Datenakquise gilt es nun, die Daten auch „zum Klingen“ zu bringen, sie aussagekräftig darzustellen. Dafür gibt es Tools „von der Stange“, etwa DataWrapper, CartoDB, Tableau und Google Docs/Fusion Tables. Werkzeuge, die für den Einstieg in die Welt der (interaktiven) Datenvisualisierung ausreichend sind. Die aber nur bedingt die Anpassung, etwa eigene Farbschema, erlauben und in ihrem Funktionsumfang eingeschränkt sind.
Wer also ernsthaft in den Datenjournalismus einsteigen will, braucht Statistik- und Programmierkompetenz: Ein Team besteht meist aus zwei oder drei Personen, die neben Recherche und journalistischen Kompetenzen die Gebiete Statistik, Programmieren und Gestaltung abdecken. (Interaktive) Visualisierungen wollen vor der Veröffentlichung gestaltet werden. Und – das wird oft im wahrsten Sinne des Wortes aus dem Auge verloren – zudem bedient werden. Das Gelingen eines interaktiven Stückes hängt maßgeblich davon ab, wie schlüssig es sich bedienen lässt („User Experience“ – UX). Je nach Komplexitätsgrad muss dafür einiges an Energie in die Planung des Bedienkonzepts gesteckt werden („Interaction Design“).
Bei der Veröffentlichung stellen sich dann Fragen zu Serverkapazitäten und anderen Webtechnologien: Soll das Angebot auch mobil nutzbar sein? Kommen Karten zum Einsatz? Sollte auch noch eine Variante der Visualisierung als printfähige Grafik ausgegeben werden können?
| Das Beispiel "Yosemite Rim Fire-Visualisierung" |
|---|
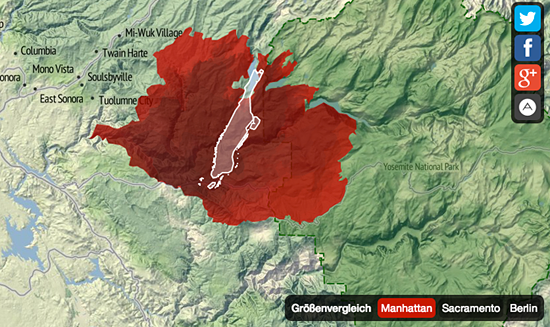 |
| Quelle: http://apps.opendatacity.de/fire/ |
| Im Sommer 2013 wütete am Rande des berühmten Yosemite-Nationalparks in den USA über Wochen ein enormer Waldbrand. Dessen Dimensionen aufzuzeigen, hatten wir uns bei OpenDataCity mit dem Projekt "Yosemite Rim Fire" vorgenommen. Auf die Idee waren wir gekommen, nachdem wir im "Incident Information System" der USA Datensätze entdeckt hatten, die die Ausbreitung des Waldbrandes als Geodaten tagesaktuell beschrieben. Sie lagen als KML-Dateien vor, die sich zum Beispiel in Google Earth öffnen lassen. Es wurde ein "Scraper" programmiert, eine kleine Software, die einmal pro Stunde kontrollierte, ob einer neuer Datensatz vorhanden war. War dies der Fall, wurde er heruntergeladen. Dieser Prozess wurde insoweit automatisiert, als dass die Anwendung auch nach der Veröffentlichung immer auf dem aktuellen Stand blieb – das Feuer brannte einige Wochen. Insgesamt waren drei Personen in die Entwicklung involviert: ein Produzent und zwei Programmierer, davon einer mit dem Schwerpunkt Datenverarbeitung, der andere mit viel Erfahrung im Bereich Grafik und Design. Die Anwendung sollte im Kern eine Animation sein, also experimentierte einer der Programmierer mit Darstellungsformen auf Basis von Javascript. Gleichzeitig entwickelten wir den Aufbau der Anwendung und ihre Funktionalität. Wichtig war uns, dass die Anwendung auch auf Smartphones lief; d.h. wir mussten auf "responsive design" setzen, das sich der Bildschirmgröße anpasst. Dafür verwendeten wir einen vorgefertigten Baustein, ein weithin genutztes Framework namens Bootstrap. Neben "Sharing"-Funktionen für Social Media wurde auch eine Option zum "Einbetten" angeboten. Da die meisten Nutzer der Anwendung wohl kaum gut mit der Region des Brandes vertraut waren, fügten wir noch Vergleichsgrößen ein, etwa die Umrisse von Berlin, die auf das Feuer projiziert werden können. Solche Umrissdaten sind frei im Netz verfügbar. Nachdem auch das digitale Kartenmaterial auf Basis der freien OpenStreetMap lief, wurde vor Veröffentlichung noch auf verschiedenen Geräten und Browsern getestet. Insgesamt sind für das Projekt so etwa 50 Stunden aufgewendet worden. |
Hohe Grundanforderungen
Damit dürfte deutlich werden: Wer regelmäßig Datenjournalismus betreiben will, muss eine technologische Infrastruktur aufbauen und vor allem auch entsprechendes Personal finden. Oder zumindest innerhalb der eigenen Strukturen datenaffine Mitarbeiter identifizieren und ihnen Freiräume schaffen: für das Experimentieren und Ausprobieren. Wichtig ist dabei auch Toleranz für Verzögerungen und Scheitern.
Letzteres stellt vielleicht die größte Herausforderung dar, weil in den meisten Abläufen so etwas bislang nicht vorgesehen ist. Doch sollte man sich unbedingt darauf einstellen, dass im Produktionsprozess angesichts der steigenden Vielfalt an Klassen von internetfähigen Geräten Probleme mit der Webtechnologie eine Menge Zeit fressen können. Das heißt, dass nicht nur aus Plausibilitätsgründen interaktive Datenanwendungen vor der Veröffentlichung ausführlich getestet werden sollten. Und schließlich muss ein Vorhaben manchmal auch abgebrochen werden. Denn manche Datensätze verraten erst nach vielen Stunden der Auseinandersetzung mit ihnen, dass nicht viel in ihnen steckt.
Lohnt sich das?
Am Ende steht selbstredend die Frage nach Aufwand und Nutzen. Gute Datenarbeit zu liefern kann ein Alleinstellungsmerkmal für das eigene journalistische Werk sein. Vor allem in Sparten, in denen noch archaische Datenzustände herrschen, also Daten kaum vorhanden oder zugänglich sind. Wenn viele Leute vom Fach von so einer Situation genervt sind, lassen sich durch einen guten Datendienst Aufmerksamkeit und Anerkennung gewinnen. Auch erfreuen sich gelungene Visualisierungen hoher Klickzahlen und finden große Resonanz in sozialen Netzwerken.
Letztlich muss klar sein: Wer regelmäßig datenjournalistische Arbeiten und Services liefern will, braucht dafür entsprechende Kompetenz und Bereitschaft in der Redaktion und dem Verlag – und letztlich auch das Kapital. Nicht zuletzt, um sich etwa Expertise, bspw. die Arbeitsleistung von Freien, einkaufen zu können. An Ausgaben in Höhe von mindestens einer niedrigen fünfstelligen Summe kommt man kaum vorbei.
Titelillustration: Esther Schaarhüls
Das Magazin Fachjournalist ist eine Publikation des Deutschen Fachjournalisten-Verbands (DFJV).
 Der Autor Lorenz Matzat arbeitet als Journalist und Software-Unternehmer in Berlin. Er gründete 2011 die Datenjournalismus-Agentur OpenDataCity mit, die er Anfang 2014 verließ. Matzat schreibt, referiert und berät weiterhin in Sachen Datenjournalismus. Mit seiner Firma Lokaler bietet er eine Kartensoftware für Location-based Services an. lokaler.de und datenjournalist.de
Der Autor Lorenz Matzat arbeitet als Journalist und Software-Unternehmer in Berlin. Er gründete 2011 die Datenjournalismus-Agentur OpenDataCity mit, die er Anfang 2014 verließ. Matzat schreibt, referiert und berät weiterhin in Sachen Datenjournalismus. Mit seiner Firma Lokaler bietet er eine Kartensoftware für Location-based Services an. lokaler.de und datenjournalist.de

[…] Weiterlesen auf fachjournalist.de […]